Benchmarks
Our test platform and specific description:
- Platform used - Dell laptop with Intel Core i7 - 11850H, Ubuntu LTS 20.04
- Every key or ciphertext block are matrix 2x2 where even 64-bit length block has overall 256-bit
- For integers all measurements were performed as 256-bit each matrix block (overall 1024)
- For float-points all measurements were performed as 64 or 128-bit length
Images demonstrating our strength and advantage you can find at the end of the explanation. So please read it to understand more or go to plots immediately [go to plots]
General understanding about FHE performance:
The performance of Fully Homomorphic Encryption (FHE) in the scope of existing schemes, such as PALISADE, SEAL etc schemes can be understood by considering as minimum these several parameters:
- Latency: This refers to the time it takes for FHE operations to be performed. Lower latency means faster encryption and decryption of data.
- Noise growth: Noise is an unavoidable side-effect of FHE operations that can accumulate over time and affect the accuracy of the results. Lower noise growth means better accuracy and reliability of the encrypted data.
- Security: the level of security depends on the specific parameters used. In general, the larger the security parameters, the stronger the security, but the slower the FHE operations.
- Hardware requirements: FHE requires significant computational resources, including processing power, memory, and storage. The hardware requirements can affect the performance and scalability of FHE solutions.
- Library support: There are several FHE libraries available, and some libraries may perform better than others depending on the specific use case. The availability of documentation, community support, and updates can also be important considerations.
Overall, FHE performance is a trade-off between security, accuracy, speed, and hardware requirements. Security parameters are values that determine the level of security provided by an FHE scheme. These parameters are chosen based on the specific security requirements of the application and the available computational resources. Generally, the larger the security parameters, the more secure the FHE scheme, but the slower the performance. General amount of problematic configuration points varies within “asymmetry”, “serialization”, “negative computations'', “encryption parameters” and “ciphertext size”, “noise budget”, “recryption”, “bootstrapping”, “relinearization” etc. The two most common security parameters used in FHE schemes are the security level and the polynomial degree. The security level determines the probability of an attacker being able to break the encryption scheme. The higher the security level, the lower the probability of an attacker breaking the encryption. The security level is typically expressed in terms of the number of bits required to represent the security level. The polynomial degree determines the size of the coefficients used in the encryption scheme. The larger the polynomial degree, the more secure the scheme, but the slower the performance. The polynomial degree is typically expressed as a power of 2, such as 2048 or 4096. Other security parameters that may be used in FHE schemes include the ring dimension, the number of moduli used, and the error distribution used. These parameters can have an impact on the security and performance of the FHE scheme and are chosen based on the specific requirements of the application. It's important to note that choosing the appropriate security parameters for an FHE scheme requires a balance between security and performance. In general, a higher level of security requires larger parameter sizes, which can result in slower performance. Therefore, it's important to carefully choose the security parameters based on the specific needs of the application - having it in mind, we can definitely say that any existing company which is offering FHE so far - can suggest to potential customers very-very poor performance with high security. If they suggest acceptable performance or anything close (which is still slow) - it 100% means they are cheating with security and sacrifice it, generally speaking breaking the idea of secure computation on encrypted data.
FHE Performance additional complexity understanding:
In the context of FHE encryption, a performance metric is often measured in terms of the number of MVE (Million Ventil-Equivalents) processed per second. For example, a performance metric of 14.35 MVE/sec means that approximately 14.35 million units of digital circuit complexity were processed per second for FHE encryption. However, the amount of encrypted information per second depends on many factors, including the size of the encrypted data, the key length used, and other parameters. Therefore, it is not possible to accurately determine the number of bits of information that can be encrypted per second based on the MVE/sec metric alone. That’s why there are no articles which you can find with clear and simple definitions like how many bits per second scheme A gives compared to scheme B etc. As stated in Table N2 in the article “New Insights into Fully Homomorphic Encryption Libraries via Standardized Benchmarks” [Table N2] of the following article https://eprint.iacr.org/2022/425, page 16, we can see how FHE performance (1 of aspects) look like and this is not standard understanding which a regular person can imagine like x amount of bits / second. No, it exactly demonstrates explained above theses about complex dependencies. But, for MathLock it's easy to understand its performance, and you can see it on our plots
MathLock Performance understanding:
In comparison to everything mentioned above, we possess a clear comprehension of performance without any complexity. As reiterated in our articles and on this website, we entirely eliminate overheads such as noise, bootstrapping, noise budget, relinearization, modulo switching, etc. Furthermore, our approach ensures zero ciphertext expansion for Integers. For floating-point numbers, expansion is solely determined by arithmetic operations, specifically increasing with each addition or subtraction operation. So general performance is related to programming language used for implementation, quality of the code, various NASM optimizations, parallelization etc. In other words pure programmatic dependencies and capabilities to deal with big numbers.
MathLock performance. At below image you can see reflected multiplicative depth performance of our scheme for both integers and floating-point
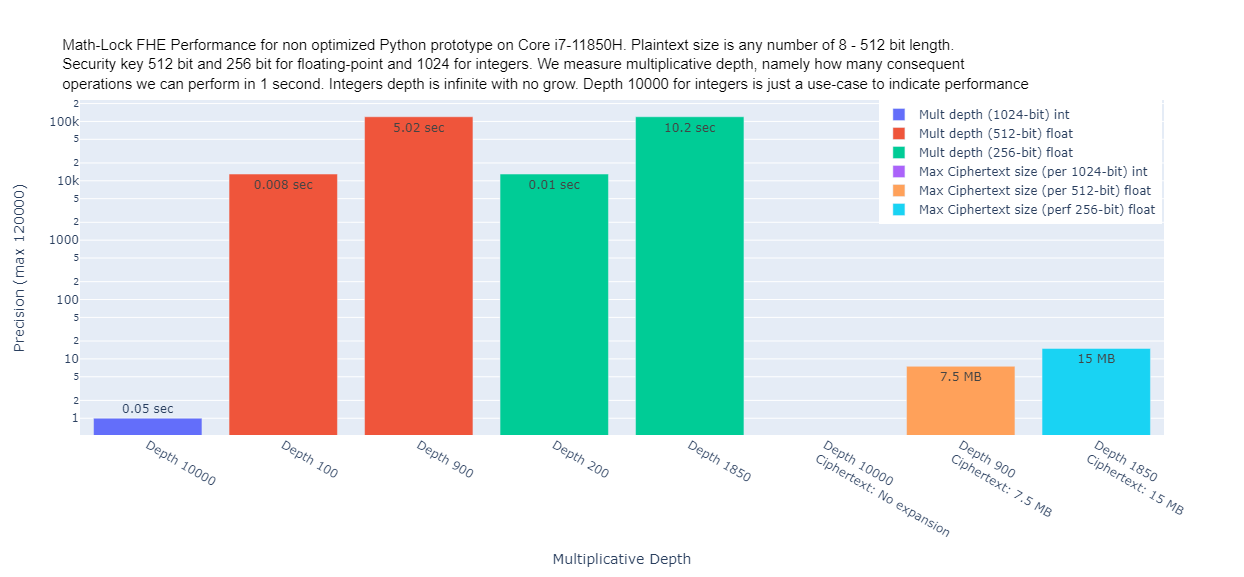
MathLock performance
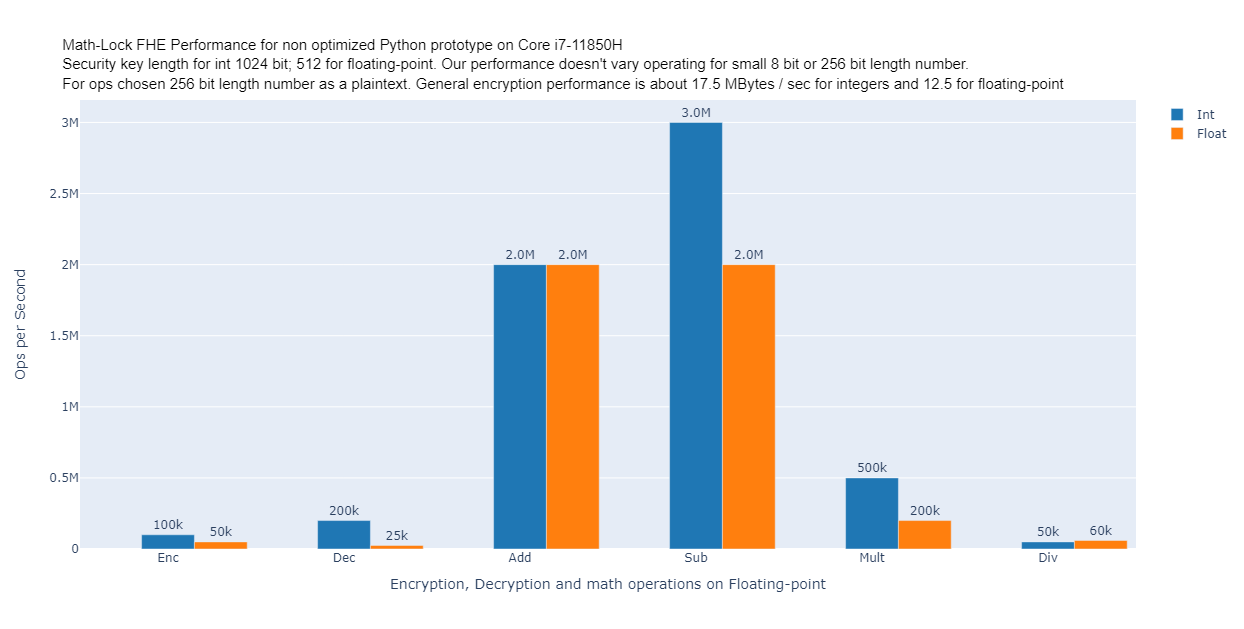
At below image you can see general performance of our scheme for both integers and floating-point
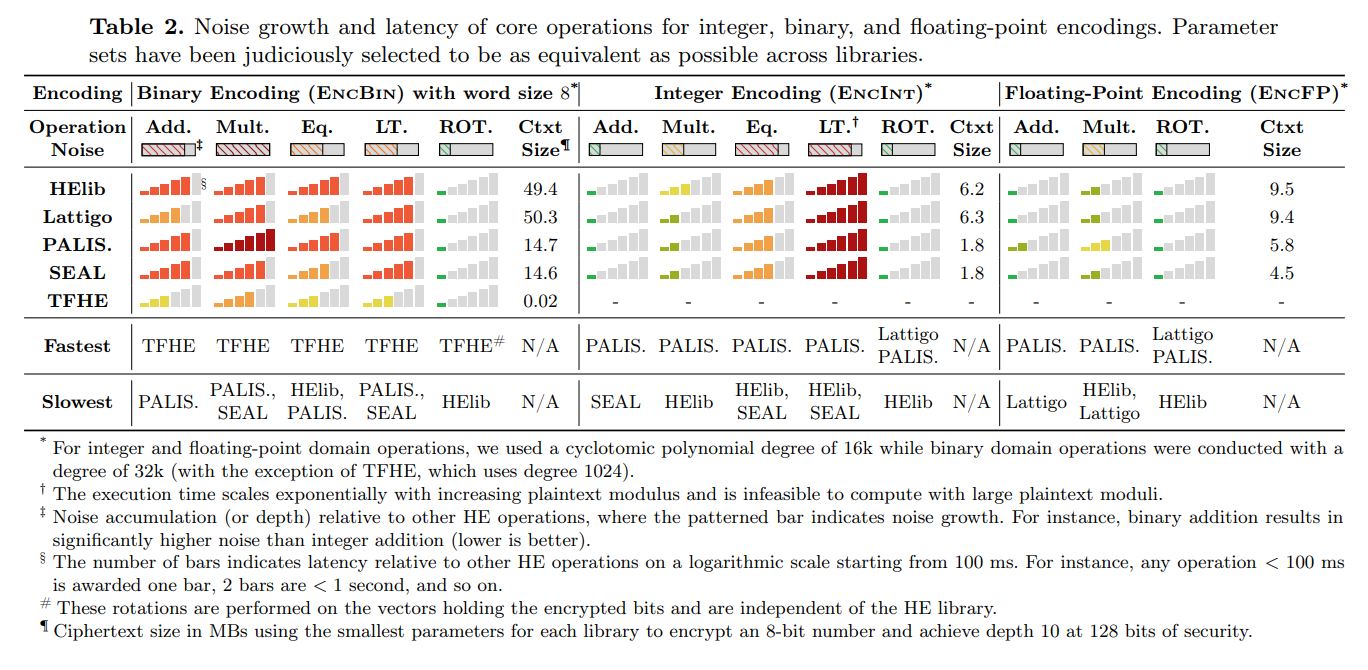
At below image we can find table reflecting performance of existing schemes. We shall also pay an attention, that performance of encryption and decryption itself isn't even provided due to its absolutely unacceptable performance. All in all to make it very short - authors of this article use 8-bit length word and 128 bit security key length. The most interesting thing for us here is floating-point operations. We can see that ciphertext size is up to 10 MBytes (raised from just 8 bits) while security params aren’t optimal and relatively small. Also, we can see that bars are indicating performance, where 1 bar is less than 100ms. We can see also, that there is no division here anywhere (all these libs as we explained before are not able to perform division). Furthermore - for multiplication every lib is awarded by 2 bars, which is marker for less than a second and this performance is just for 8 bits word to perform 1 single multiplication. Easy to imagine how slow FHE for all existing schemes is.
Doing comparison with any existing solution, for multiplicative depth == 20:
- Using bit depth 128 x 4 - we need 850 precision for valid answer, then we do 20 depth in 0.00176 seconds
- Using bit depth 64 x 4 - we need 1400 precision for valid answer, then we do 20 depth in 0.00022 seconds
- While our competitors can do max 20-30 ops, which is max possible limit, in about 7-14 seconds (without taking into account bootstrapping, noise budget etc overheads, which will increase it for minutes). and it's within 31.818-63.636 times slower (without bootstrapping and denoise), and minimum 272.727 times slower with bootstrapping and denoise.